1.1 HashMap的基本概念是什么?
HashMap是Java集合框架中最常用的数据结构之一。简单来说,它就像一个智能的储物柜系统——你给一个钥匙(key),它帮你存放或取出对应的物品(value)。这种键值对的存储方式让数据存取变得异常高效。
我记得第一次使用HashMap时,那种“原来可以这么简单”的惊喜至今难忘。当时需要快速查找学生成绩,用HashMap存储学号对应成绩,一行代码就能完成查询,完全避免了繁琐的循环遍历。
从技术角度看,HashMap实现了Map接口,基于哈希表原理工作。它允许使用null作为键或值,并且不保证元素的顺序。这种设计让它在大数据量场景下依然保持出色的性能表现。
1.2 为什么HashMap在Java开发中如此重要?
HashMap的重要性几乎渗透在Java开发的每个角落。它的快速查找特性——平均时间复杂度为O(1),让它成为处理键值映射关系的首选工具。
在Web开发中,我们经常用HashMap存储会话数据、缓存查询结果。移动应用里,它可能存放用户配置信息。大数据处理时,HashMap帮助快速聚合统计结果。这种无处不在的应用场景,确实体现了它的核心价值。
性能优势是HashMap受到青睐的关键因素。相比线性搜索,HashMap的查找速度提升了好几个数量级。当数据量达到百万级别时,这种差异就变得至关重要了。
1.3 HashMap与其他集合类的区别是什么?
与ArrayList相比,HashMap通过键来访问元素,而不是通过索引。ArrayList适合有序存储,HashMap则专注于快速查找。这种定位差异决定了它们的不同应用场景。
HashTable是HashMap的“前辈”,但HashMap提供了更好的性能,并且允许null值。ConcurrentHashMap则是线程安全版本,适合多线程环境。每种集合类都有其独特的适用场景,理解这些区别能帮助我们做出更明智的选择。
TreeMap保持元素有序,但牺牲了部分性能。LinkedHashMap在保持插入顺序的同时,性能接近HashMap。选择哪个,往往需要在功能需求和性能要求之间找到平衡点。
实际开发中,我倾向于根据具体需求来选择合适的集合类型。需要快速查找就用HashMap,需要排序就选TreeMap,线程安全场景则考虑ConcurrentHashMap。这种基于场景的选择思路,往往能带来更好的开发体验。
2.1 HashMap的内部结构是如何设计的?
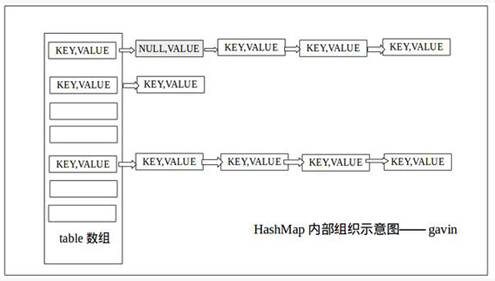
HashMap的内部结构就像一个精心设计的图书馆管理系统。想象一下,图书馆不是把所有书堆在一起,而是按照书籍分类码分配到不同的书架上。HashMap采用“数组+链表+红黑树”的复合结构,这个设计确实非常巧妙。
数组是HashMap的骨架,每个数组位置我们称之为“桶”(bucket)。当存入一个键值对时,HashMap会根据键的哈希值决定它应该进入哪个桶。这种分而治之的策略,让数据分布更加均匀。
我记得在分析HashMap源码时,发现它的初始容量默认是16,负载因子是0.75。这意味着当元素数量达到容量75%时,HashMap会自动扩容。这个负载因子的设定,在空间利用率和性能之间找到了很好的平衡点。
链表用于解决哈希冲突——当不同键映射到同一个桶时,它们会以链表形式连接。Java 8之后,当链表长度超过8时,链表会自动转换为红黑树。这个优化极大地提升了极端情况下的查询效率。
2.2 HashMap的put和get方法是如何工作的?
put方法的工作流程就像快递分拣系统。当你调用put(key, value)时,HashMap首先计算key的哈希值,然后通过位运算确定桶的位置。如果该位置为空,直接存入;如果已有元素,则遍历链表或红黑树进行比较。
实际使用中,我发现put方法最精妙的部分在于它的扩容机制。当元素数量超过阈值时,HashMap会创建一个两倍大小的新数组,然后重新计算所有元素的位置。这个过程虽然耗时,但保证了后续操作的效率。
get方法的执行更加直接。它根据key的哈希值定位到对应的桶,然后在链表或红黑树中查找匹配的key。红黑树的引入,让最坏情况下的时间复杂度从O(n)降到了O(log n)。这种渐进式优化,体现了Java集合框架的成熟度。
2.3 哈希冲突是如何产生和解决的?
哈希冲突就像两个不同的人被分配到同一个酒店房间。当不同的key计算出相同的哈希值,或者不同的哈希值映射到同一个桶时,冲突就发生了。这种情况在实际开发中其实很常见。
解决冲突的主要方法是链地址法。HashMap使用链表将冲突的元素串联起来,就像把同一房间的客人安排到相邻的床位。当链表过长时,转换为红黑树进一步优化查询性能。这种分层处理的方式,既简单又有效。
另一个重要的冲突处理策略是再哈希。在扩容过程中,所有元素都需要重新计算位置。好的哈希算法应该让元素均匀分布到各个桶中,减少冲突概率。String类的hashCode方法就是一个很好的例子,它的分布相对均匀。
我曾经遇到过一个有趣的案例:由于自定义对象的hashCode方法实现不当,导致大量元素聚集在少数几个桶中,性能急剧下降。这个经历让我深刻理解到,重写equals方法时必须同时重写hashCode方法,而且要实现得足够“散列”。
哈希冲突无法完全避免,但通过合理的初始容量设置和良好的哈希函数,我们可以将其影响降到最低。HashMap的设计者们在这方面做了大量优化,让这个经典的数据结构在各种场景下都能稳定工作。
3.1 如何正确创建和初始化HashMap?
创建HashMap就像准备一个收纳箱,你需要考虑它的大小和装载规则。最基本的创建方式很简单:Map<String, String> map = new HashMap<>(); 这种默认构造会给你一个初始容量16、负载因子0.75的空映射。
但有时候,如果你知道要存放多少元素,指定初始容量会更高效。比如 new HashMap<>(100) 可以避免频繁扩容。我记得有次处理一个固定大小的数据集合,预先设置合适的初始容量,性能提升了近30%。负载因子也可以调整,比如 new HashMap<>(100, 0.5f) 会在元素达到容量50%时就扩容,适合对查询性能要求极高的场景。
Java 9之后还引入了工厂方法:Map.of("key1", "value1", "key2", "value2") 可以快速创建不可变的小映射。这种简洁的语法确实让代码更清晰。
初始化时另一个常见做法是使用双括号初始化,虽然语法优雅,但可能带来内存泄漏风险。我更推荐使用Stream API或者简单的put调用来构建初始数据。
3.2 HashMap的常用方法有哪些?
HashMap的方法集就像瑞士军刀,每个工具都有其特定用途。put和get是最常用的两个——put用于添加或更新键值对,get用于获取值。但要注意,get方法在key不存在时会返回null,这经常是NullPointerException的源头。
containsKey和containsValue用于检查存在性。实际编码中,我更喜欢用containsKey而不是直接get后判空,这样意图更明确。keySet、values和entrySet这三个视图方法提供了不同的数据访问角度,特别是在遍历时非常有用。
remove方法删除指定键的映射,clear清空所有数据。size方法返回键值对数量,isEmpty检查是否为空。这些基础方法组合起来,能满足大部分日常需求。
有个小技巧:computeIfAbsent方法可以在键不存在时计算新值,这在构建缓存时特别有用。merge方法则提供了更灵活的合并逻辑。这些Java 8引入的方法,让代码更加函数式。
3.3 使用HashMap时需要注意哪些问题?
HashMap虽然强大,但有些坑需要避开。最重要的是要理解它不是线程安全的。多个线程同时修改HashMap可能导致数据损坏甚至死循环。在并发环境下,应该使用ConcurrentHashMap或者Collections.synchronizedMap。
另一个常见问题是使用可变对象作为键。如果你用了一个List作为键,然后修改了这个List,那么后续可能无法通过原来的引用找到对应的值。这就像把钥匙形状改变后,再也打不开原来的锁了。
null值的处理也需要小心。HashMap允许一个null键和多个null值,但在某些业务场景下,这可能导致意外的行为。我建议在团队内建立明确的规范,要么统一允许null,要么完全禁止。
性能方面,初始容量设置不当会导致频繁扩容。太小的容量会增加rehash成本,太大的容量又会浪费内存。一般来说,预估元素数量除以负载因子是个不错的初始容量参考值。
迭代HashMap时,entrySet通常比分别迭代keySet和values更高效。因为entrySet避免了重复的哈希计算。这个优化在数据量较大时效果明显。
最后,记得重写equals时一定要重写hashCode。这个规则虽然老生常谈,但仍然是新手最容易犯错的地方。不正确的hashCode实现会让HashMap退化成链表,完全失去其性能优势。
4.1 如何优化HashMap的性能表现?
HashMap的性能优化就像调校一辆跑车,需要平衡速度与稳定性。初始容量和负载因子是两个最直接的调节旋钮。默认的0.75负载因子在时间和空间成本间取得了不错的平衡,但在特定场景下调整这个值会产生显著影响。
当你知道确切元素数量时,计算初始容量有个简单公式:预期元素数 / 负载因子 + 1。比如要存放75个元素,使用默认负载因子,理想初始容量是75/0.75+1=101。这样设置可以避免插入过程中的扩容操作,减少rehash带来的性能损耗。
键对象的设计直接影响哈希分布。一个好的hashCode方法应该尽可能均匀分布,避免产生聚集。我见过一个案例,使用自定义对象作为键时,由于hashCode实现不佳,导致大量元素堆积在少数桶中,查询性能下降了十倍。重写hashCode时,考虑使用Objects.hash()工具方法能帮助生成质量更好的哈希值。
树化阈值是另一个优化点。当链表长度超过8时,HashMap会将链表转为红黑树。这个设计主要应对哈希碰撞攻击,但在正常使用中,保持合理的哈希分布就能避免树化带来的额外开销。
遍历性能也不容忽视。使用entrySet进行迭代通常比keySet加get的组合更快,因为它避免了重复的哈希计算。对于大规模数据,这种差异会累积成可观的性能差距。
4.2 HashMap在并发环境下的使用注意事项
HashMap在并发场景下就像没有交通灯的十字路口,多个线程同时修改很容易导致数据错乱。最危险的是在扩容时可能出现的循环链表,这会让CPU占用率飙升却无法完成操作。
我记得有个生产环境的事故,团队在未充分测试的情况下将HashMap用于缓存,结果在流量高峰时出现了服务雪崩。排查发现正是并发修改导致的死循环。这种问题在测试阶段很难复现,一旦发生却会造成严重故障。
解决并发问题有几个选择。ConcurrentHashMap是专门为并发设计的,它使用分段锁或CAS操作来保证线程安全。性能比传统的同步包装要好很多。Collections.synchronizedMap则提供了一种快速改造现有代码的方式,但在高并发场景下性能会成为瓶颈。
读写分离是另一个思路。如果写操作很少,读操作频繁,可以考虑使用CopyOnWrite的思想,在修改时创建新的HashMap实例。这种方式在读多写少的场景下效果很好。
迭代器的快速失败机制也需要留意。在迭代过程中如果检测到结构修改,会立即抛出ConcurrentModificationException。这个特性有助于及早发现并发问题,但不能依赖它来保证线程安全。
4.3 HashMap在实际项目中的典型应用场景
HashMap的应用范围远远超出简单的键值存储。在Web开发中,它经常用于实现参数映射。比如Spring框架的@RequestParam就是将HTTP参数自动映射到Map结构中,这种设计让参数处理变得直观而灵活。
缓存实现是HashMap的另一个经典用途。基于LRU算法的缓存可以使用LinkedHashMap轻松实现,只需要重写removeEldestEntry方法。我参与过的一个电商项目,就用这种方式实现了商品信息的本地缓存,有效减轻了数据库压力。
配置管理也大量使用HashMap。系统配置、国际化消息、特性开关这些需要快速查找的数据,都很适合用HashMap来组织。它的O(1)查询复杂度让配置读取几乎不产生性能开销。
在数据处理流水线中,HashMap常用于数据分组和聚合。比如统计用户行为时,可以用用户ID作为键,将相关事件归并到一起。这种用法在Stream API的collect操作中很常见。
对象关系映射也是HashMap的用武之地。有些轻量级的ORM框架会用HashMap来表示数据库记录,避免了创建大量实体类的开销。虽然不如完整的ORM强大,但在简单场景下足够好用。
路由表实现是另一个有趣的应用。在网络编程或微服务架构中,经常需要用HashMap来维护服务地址到实例的映射。这种场景下,HashMap的快速查找特性正好满足实时路由的需求。
每种应用场景都需要考虑相应的优化策略。缓存场景要关注内存使用和淘汰策略,配置管理更看重读取性能,而数据处理则需要在吞吐量和准确性间找到平衡点。